The Retresco integration uses semantic analysis and keywording to tag documents with relevant entities. These entities are then stored within a document’s metadata and can be used to categorise documents.
Please be aware that Retresco may need to enable an additional feature on your setup for the integration to work. The key feature required is the rtr_payload object in the Retresco POST /api/entities response. This object should exist when there are one or more entities in the rtr_* arrays in the response. If the object is not returned then please contact Retresco to upgrade your instance so that is compatible with Livingdocs.
Configuration
Server
Enable the integration on the server level by setting allowed: true. You can also set ensureExtraction: true if you would like to ensure the entities are up-to-date when publishing a document.
{
// ...
integrations: {
// ...
retresco: {
allowed: true,
ensureExtraction: true
}
}
// ...
}
 For the test environment it is recommended to either disable the Retresco integration with
For the test environment it is recommended to either disable the Retresco integration with allowed: false, or to set registerHooks: false to prevent the integration from interfering during publish and unpublish events.Project
Each project also needs to be configured to use the Retresco integration. You must set enabled: true to activate the feature, and provide the Retresco API endpoint and credentials.
{
// ...
settings: {
// ...
integrations: {
// ...
retresco: {
enabled: true,
apiEndpoint: 'https://<subdomain>.rtrsupport.de/',
username: '<username>',
password: {
$secretRef: {
name: '<secret-name>' // See Project Secret section below
}
},
enableLiveAnalysis: true,
enableMainEntityOverride: true, // Optional
titleMatches: ['header.title'],
supertitleMatches: ['header.catchline'],
teaserMatches: ['p.text'],
maxTextLength: 10000, // Optional
enrichConcurrency: 5 // Optional
}
// ...
}
// ...
}
// ...
}
Text Extraction
You can also optionally provide the text extraction “matches”. titleMatches, supertitleMatches, and teaserMatches are arrays of <component-name>.<directive-name> strings which can be used to extract the text content and deliver them to the Retresco API in the relevant fields within the request payload. Only the first match found for each field will be used, but multiple values can be provided so that many content types can be supported.
enableLiveAnalysis
The default behaviour is to analyse the text on the idle event, typically 5 seconds after a user stops typing, so that the tags are always up-to-date with the content. If you would like to prevent text analysis while a user is working on a document it is possible to set enableLiveAnalysis: false. Once disabled the only way the tags will be updated is by the user clicking the refresh button in the metadata form, or at the time of publication.
maxTextLength
The Retresco API can have issues if the text sent for analysis is too long (more than 10.000 characters). To avoid errors with longform articles, you can optionally set a maxTextLength, this will limit the number of characters of text being sent in the request.
enableMainEntityOverride
Retresco marks the strongest tags in a document as “main entities”. By default this state is stored but not editable by users in the editor. Set enableMainEntityOverride: true to show a star toggle on each tag so editors can promote or downgrade main entities themselves (Added in: release-2026-07).
Before enabling this option, check with Retresco that main entities are enabled on your setup.Content Type
You will need to add the metadata plugin for all content types that you would like to analyze. You may provide any handle for the Retresco metadata field. The li-retresco type is essential.
{
metadata: [{handle: 'retresco', type: 'li-retresco'}]
}
Project Secret
Finally, a secret must be added for the relevant <project-handle>. The <secret-name> should match the value of the password.$secretRef.name property in the Retresco integration’s project config object. The <password> should be the password provided by Retresco used to access the API. Within a development or test environment it is also possible to seed this value.
npx livingdocs-server secret-add --project="<project-handle>" --name="<secret-name>" --value='<password>'
For more information on how to use secrets, please check Project Secrets.
Metadata
The Retresco entities will be stored in the document’s metadata using the metadata plugin’s handle as the property name. The value is an object which contains the latest contentVersion the entities were extracted from, along with an array of entities returned by the Retresco API.
{
contentVersion: '1006.2', // <revision-id>.<revision-version>
entities: [
{
id: '3f9d52ff1f8c660174c0ac44d141cc71e5de0569',
name: 'Zürich',
type: 'location',
score: 16.924834941594718, // Only when not user-added
userAdded: false,
inappropriate: false, // Entity removed (but still visible in the UI with strikethrough)
isMain: true, // Marks main entities (Added in: release-2024-09)
userOverrideIsMain: true // Set when an editor changed the main state (Added in: release-2026-07)
}
]
}
Main Entities
Added in: release-2026-07
Retresco marks the strongest tags in a document as main entities in the isMain field. When enableMainEntityOverride is enabled on the project, editors can override this verdict with a star toggle on each tag.
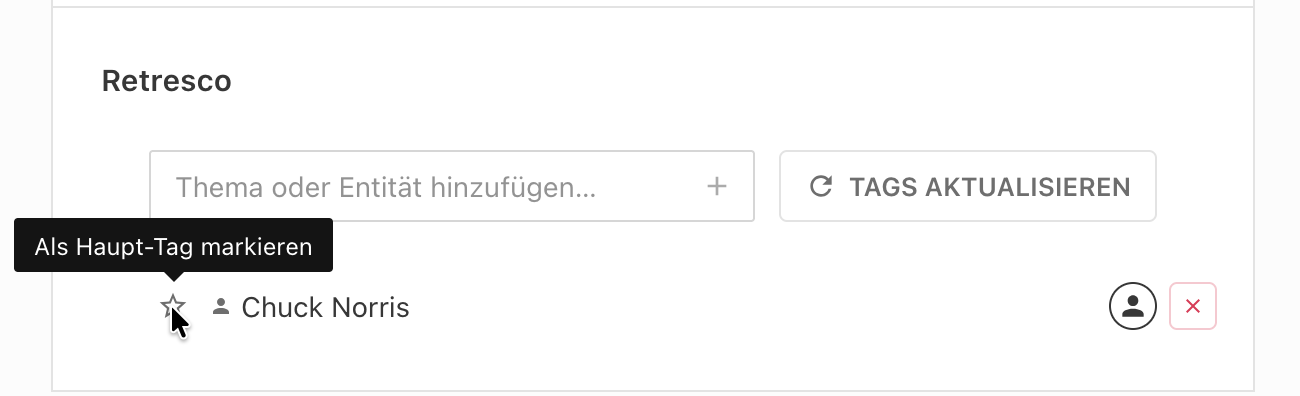
Toggling a tag stores the new value in isMain and sets userOverrideIsMain: true. Once set, the tag stays even if Retresco no longer detects it, and re-enrichment no longer overwrites the editor’s choice.
Re-enrich Documents
Added in: release-2023-03
If you want to use the re-enrich feature from Retresco, you will need to configure the webhook and token in Retresco’s website.
The Livingdocs webhook URL is https://<livingdocs-server>/api/2026-07/retresco/re-enrich. The token can be obtained by a project administrator user in the Livingdocs Editor following the steps below:
- Make sure you are in the project you want to enable the Retresco hook
- In the main project menu select “Project Admin”
- Then select “Api Clients” in the left menu
- Click the “Add API Client” button on the right
- Define desired expiration date from the dropdown
- Enter a descriptive name, provide permission for retresco hook access, and click the “Create” button
- The token will be displayed in the table, copy it and save it in a safe place, you will have to use it on Retresco’s website. Please note that the token will not be displayed again after you leave the page
The HTTP endpoint will be called by Retresco when the user modifies entities that apply to one or multiple documents. The request will generate a job queue that will handle document enrichment and update the metadata asynchronously. The document will be automatically published if enrichment was the only change since the last publication, i.e. there wasn’t a draft for the document.
It is possible to configure the enrich job concurrency by setting the integrations:retresco:enrichConcurrency property in the server configuration. The value must be a positive integer. Retresco recommends a maximum value of 10 concurrent request to their enrich endpoint. Their enrich endpoint takes 0.5s-1s to process a request.