Architecture diagrams source files can be found on google drive
Editing stack
The editing stack is usually accessed by a limited number of editorial users and hence requirements for redundancy are lower than in the delivery stack. For that reason, we do not recommend to add a caching layer to the editing stack.
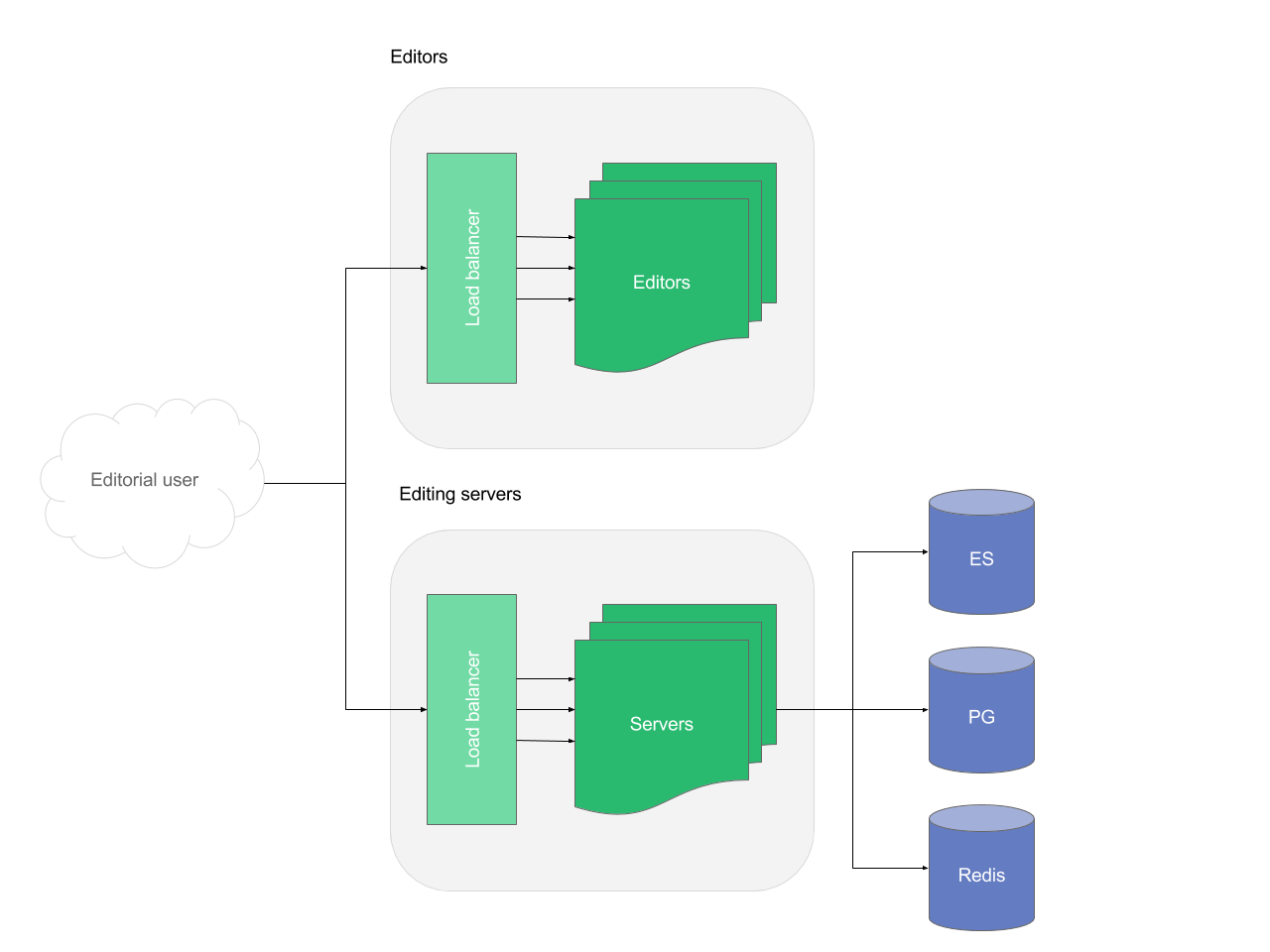
- Editor: It is unlikely that it needs scaling as it only serves static assets. If it had to be redundant, you can always run two instances behind a load balancer.
- Editing servers: It should be scaled based on the load generated by the editorial users. Due to Node.js processes nature, it is always recommended to run redundant with at least three processes, even in a simple production setup.
- Elasticsearch (ES): It should be scaled based on the number of objects in the database (mainly articles and pages) and read/write throughput. The load generated by the editorial users is usually very low and does not need special considerations. Redundancy can be achieved through configuring shards and replicas.
- Postgres (PG): It should be caled based on the number of objects in the database (mainly articles and pages) and read/write throughput. The load generated by the editorial users is unlikely to require PG scaling. Redundancy can be achieved through standby servers and failover.
- Redis: Scaled based on the number of objects in the key-value store (mainly routes for articles, pages and queue jobs) and read/write throughput. Redundancy can be achieved through configuring replication.
Delivery stack
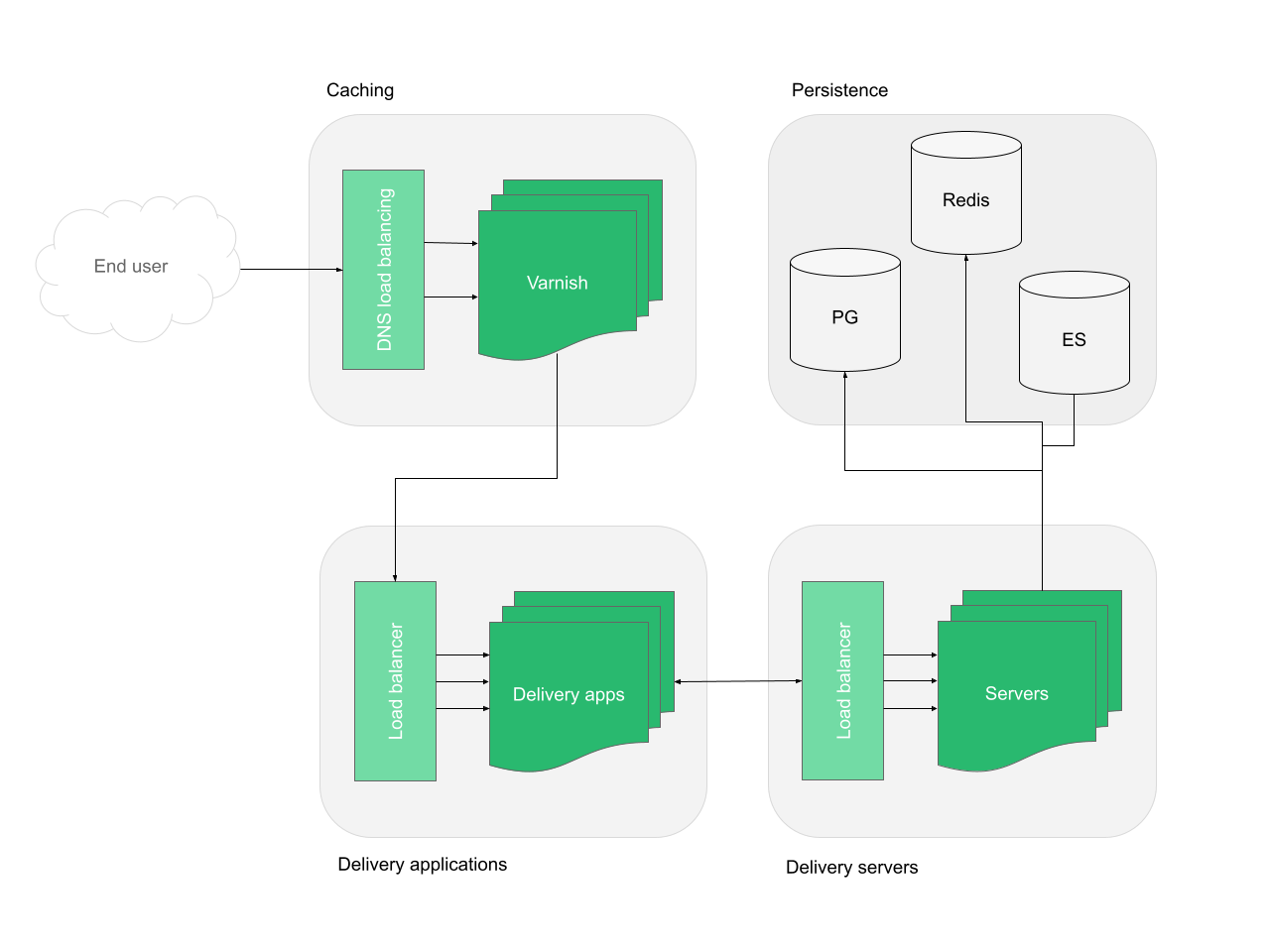
- Caching: The entry point is a Varnish cache server. Redundancy can be achieved through DNS load balancing.
- Delivery applications: It should be scaled based on the load generated by the end users. Due to Node.js processes nature, it is always recommended to run redundant with at least three processes, even in a simple production setup.
- Delivery servers: It should be scaled based on the load generated by the end users. Due to Node.js processes nature, it is always recommended to run redundant with at least three processes, even in a simple production setup.
- Elasticsearch (ES): It should be scaled based on the load generated by end users. In most cases, ES instance can be a shared database with the editing stack. Separation of stacks can be achieved setting up a custom index for publications. Redundancy can be achieved through configuring shards and replicas.
- Postgres (PG): It should be scaled based on the load generated by the end users. In most cases, Delivery stack PG’s instance can be shared with the editorial stack. Separation of the two stacks can be achieved with a read only replica database within the delivery stack, following the data from the read/write main database in the editing stack. Redundancy can be achieved through standby servers and failover.
- Redis: It should be scaled based on the read/write load. In most cases, it can be a shared database with the editing stack. Redundancy can be achieved through configuring replication.